
唐剛老師: Cloudera原廠授權(quán)講師。北航碩士,10年IT研發(fā)與培訓(xùn)經(jīng)驗(yàn),對Java、Hadoop、Scala、Spark、數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)等大數(shù)據(jù)技術(shù)具有深厚的技術(shù)功底,曾參與開發(fā)電商日志分析、廣告實(shí)時(shí)推薦、金融異常交易預(yù)警、基于GPS的實(shí)時(shí)路況分析、超速頻發(fā)路段監(jiān)控等項(xiàng)目。

5、6年前,大數(shù)據(jù)的概念還不為人所知,Hadoop更是沒幾個(gè)人知道,唐剛老師由于工作上的因緣,幸運(yùn)的成為最早接觸并使用Hadoop進(jìn)行大數(shù)據(jù)開發(fā)的那批人。在后來的日子,他沒有像其他人那樣去大公司做高管或者創(chuàng)業(yè),而是慢慢走上了大數(shù)據(jù)開發(fā)的培訓(xùn)之路。
唐剛老師認(rèn)為技術(shù)講師是一份對人要求更高的工作,不僅要走在技術(shù)的前沿,還要善于講解和表達(dá)。五年多來,他一直在大力推行Hadoop和Spark,但仍有不少人對這兩種開發(fā)工具的運(yùn)用表示困惑或帶有誤解。在采訪中,唐剛老師結(jié)合自己的經(jīng)歷,探討了Hadoop和Spark的優(yōu)劣和應(yīng)用,并給出了學(xué)習(xí)建議和學(xué)習(xí)路徑,數(shù)據(jù)妞希望能對有志轉(zhuǎn)型大數(shù)據(jù)或步入大數(shù)據(jù)行業(yè)的人有所幫助。
數(shù)據(jù)妞:能否談?wù)勀cHadoop的接觸經(jīng)歷?
唐剛:我大學(xué)讀的是計(jì)算機(jī),但那時(shí)候我對編程其實(shí)沒有什么興趣。在學(xué)校里我們學(xué)的是C語言、匯編語言等等,采用的都是DOS界面,非常枯燥。這種感覺直到接觸VB才大大改變,因?yàn)閂B是有可視化效果的,我才覺得原來編程也挺好玩的。后來我又接觸了Java,畢業(yè)之后就一直在做Java開發(fā)。
2010年到2011年那時(shí),我工作的公司要做一個(gè)Java Web的項(xiàng)目,數(shù)據(jù)量非常大,用Java去查詢數(shù)據(jù)的時(shí)候速度非常慢,我們就想辦法如何去解決這個(gè)問題。那段時(shí)間我在一個(gè)國外的技術(shù)網(wǎng)站上看到了Hadoop,我才知道原來還有這樣一個(gè)東西,它可以有效提升數(shù)據(jù)處理的速度,于是我在一次公司例會(huì)上提議學(xué)習(xí)Hadoop。
那時(shí)候國內(nèi)幾乎沒人用Hadoop,就連知道的人也很少,我們學(xué)習(xí)途徑主要就通過Hadoop的官方網(wǎng)站。另外幸運(yùn)的是,我有一個(gè)朋友當(dāng)時(shí)在讀研,他的研究生畢業(yè)論文就是要用Hadoop 去做的,于是我有什么問題就向這個(gè)朋友討教。
我們大概花了半年時(shí)間才完成了轉(zhuǎn)型,可以說非常吃力。一是當(dāng)時(shí)學(xué)習(xí)途徑很狹窄,沒有中文資料,也沒有什么書籍,資料匱乏,一個(gè)組件可能就要研究很長時(shí)間。二是時(shí)間少,我要在完成本職工作之后再抽時(shí)間一點(diǎn)一點(diǎn)學(xué)。不過雖然辛苦,但帶給我最大的好處就是我很早就與大數(shù)據(jù)開發(fā)結(jié)緣。
數(shù)據(jù)妞:您目前的工作是什么,為何有這樣的職業(yè)選擇?
唐剛:目前我在光環(huán)國際擔(dān)任大數(shù)據(jù)教學(xué)總監(jiān),主要工作是針對大數(shù)據(jù)開發(fā)方面的培訓(xùn)。
以前和我一起學(xué)習(xí)Hadoop的人現(xiàn)在基本都混得很不錯(cuò),有不少人都在做CTO或是總監(jiān)級別的了。而我是因?yàn)樵?011年之前曾在一些培訓(xùn)機(jī)構(gòu)兼職講課,從那時(shí)候開始就漸漸喜歡上了講課,于是我跳槽之后就去了一家IT培訓(xùn)公司,一邊大力推廣Hadoop,一邊做大數(shù)據(jù)項(xiàng)目的研發(fā)。
我認(rèn)為做技術(shù)講師是一件高難度的工作。做技術(shù)講師首先要懂技術(shù),要保持自己技術(shù)的先進(jìn)性,其次你要能準(zhǔn)確、合適地進(jìn)行表達(dá),因?yàn)榧夹g(shù)是很抽象、很枯燥、很難理解的東西,你需要用近似于“大白話”的方式去說明專業(yè)的技術(shù)問題,這個(gè)對人的提高是很大的。我現(xiàn)在也一直在研究前沿技術(shù),最近我一直在研究Spark和機(jī)器學(xué)習(xí)。
數(shù)據(jù)妞:您認(rèn)為是什么造成了Hadoop的流行?
唐剛:Hadoop之所以能流行主要是因?yàn)榇髷?shù)據(jù)對存儲、處理的要求比傳統(tǒng)數(shù)據(jù)要高得多。
由于互聯(lián)網(wǎng)(特別是移動(dòng)互聯(lián)網(wǎng))的發(fā)展,每天都會(huì)產(chǎn)生大量的數(shù)據(jù),產(chǎn)生數(shù)據(jù)的渠道比之前也多了很多。這些數(shù)據(jù)通過日積月累就會(huì)變成海量的大數(shù)據(jù)。
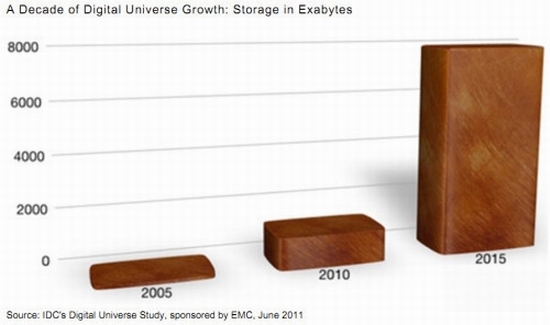
2011年全球被創(chuàng)建和復(fù)制的數(shù)據(jù)總量為1.8ZB(10的21次方),其中75%來自于個(gè)人,遠(yuǎn)遠(yuǎn)超過人類有史以來所有印刷材料的數(shù)據(jù)總量(200PB)。過去幾年全世界產(chǎn)生的數(shù)據(jù)量甚至超過了歷史上2萬年來產(chǎn)生的數(shù)據(jù)量的總和。(資料來源:IDC研究報(bào)告《從混沌中提取價(jià)值》)
現(xiàn)在人們常說的數(shù)據(jù)挖掘、數(shù)據(jù)分析并不是新的東西,在之前已經(jīng)存在很久了。但大數(shù)據(jù)時(shí)代和以前不一樣,大數(shù)據(jù)如果還用以前的手段進(jìn)行存儲、分析是很困難的。然而Hadoop在處理海量大數(shù)據(jù)方面就非常有優(yōu)勢,所以可以說Hadoop是應(yīng)大數(shù)據(jù)時(shí)代之勢而流行起來。
Hadoop的優(yōu)勢主要體現(xiàn)在兩方面:第一,它可以通過HDFS把數(shù)據(jù)進(jìn)行分布式的存儲,這就解決了大數(shù)據(jù)的存儲問題;第二,它有MapReduce,通過編寫Map函數(shù)和Reduce函數(shù)解決了大數(shù)據(jù)的計(jì)算處理問題。目前Hadoop在大數(shù)據(jù)開發(fā)領(lǐng)域仍然占主流。
數(shù)據(jù)妞:Spark是何時(shí)發(fā)展起來的?Spark會(huì)取代Hadoop嗎?
唐剛:Spark大概是在2013年傳入中國的,在2014年左右就出現(xiàn)了一些觀點(diǎn),認(rèn)為Spark會(huì)取代Hadoop,或者“Spark一出,Hadoop必死”。但是我始終認(rèn)為,大數(shù)據(jù)開發(fā)這個(gè)行業(yè)肯定是百家爭鳴、多平臺共存的行業(yè)。直到目前,我們也發(fā)現(xiàn)Hadoop并沒有因?yàn)镾park的出現(xiàn)而消亡,Hadoop和 Spark都有它的優(yōu)勢和劣勢。
從數(shù)據(jù)存儲的角度來看:目前Spark生態(tài)體系中缺少一個(gè)類似于Hadoop的HDFS的子項(xiàng)目。HDFS(文件分布式系統(tǒng))屬于Hadoop生態(tài)體系的,是一個(gè)非常優(yōu)秀的分布式文件系統(tǒng),解決了大數(shù)據(jù)的存儲問題,還有YARN平臺也是一個(gè)非常優(yōu)秀的資源管理系統(tǒng)。Spark缺少像HDFS這樣一個(gè)框架,所以Spark要依賴于HDFS來進(jìn)行存儲。Spark在進(jìn)行開發(fā)時(shí)也會(huì)用到Y(jié)ARN平臺或者M(jìn)esos。
從數(shù)據(jù)處理速度的角度看:相比Spark,Hadoop最大的問題是處理速度慢。MapReduce產(chǎn)生的中間結(jié)果是放到磁盤當(dāng)中的,如果我要用到Map產(chǎn)生的中間結(jié)果,我需要先從磁盤中讀取到內(nèi)存中再使用,如果又產(chǎn)生一個(gè)中間結(jié)果,這個(gè)中間結(jié)果又要先放到磁盤當(dāng)中,再從磁盤讀取到內(nèi)存當(dāng)中才能使用,所以說MapReduce存在無法避免的磁盤輸入輸出的過程,這在速度上是一個(gè)很大的缺陷。
但是Spark就不一樣了。Spark處理數(shù)據(jù)所產(chǎn)生的中間結(jié)果放在內(nèi)存中,要用的時(shí)候直接從內(nèi)存讀取就可以了,少了磁盤輸入輸出的過程,速度比Hadoop要快。
從編碼的角度看:在MapReduce中,需要編寫Map函數(shù)和Reduce函數(shù),不管做什么處理,必須編寫這2個(gè)函數(shù)。Hadoop的源碼是Java,用Java編寫MapReduce比較麻煩、繁瑣,有時(shí)候代碼量也挺大的。
Spark的源碼是Scala,Scala寫起來比較簡潔,所以用Scala來開發(fā)Spark要簡單得多。
Hadoop在目前大數(shù)據(jù)開發(fā)的領(lǐng)域仍然占主流,但是Spark的發(fā)展速度是非常快的,它是一個(gè)非常有發(fā)展?jié)摿Φ目蚣堋adoop更加偏向于離線批處理,Spark既可以進(jìn)行離線批處理計(jì)算,也可以進(jìn)行交互式計(jì)算,還可以對數(shù)據(jù)流進(jìn)行準(zhǔn)實(shí)時(shí)計(jì)算。
數(shù)據(jù)妞:國內(nèi)外對Hadoop和Spark的應(yīng)用情況如何?
唐剛:Hadoop、Spark的實(shí)際應(yīng)用有很多。包括政府的輿情管理,例如我國的網(wǎng)絡(luò)輿情監(jiān)測系統(tǒng);電信行業(yè),例如移動(dòng)、聯(lián)通這樣的電信運(yùn)營商做精準(zhǔn)營銷(客戶畫像、關(guān)系鏈研究、實(shí)時(shí)營銷和個(gè)性化推薦等);電商行業(yè),如淘寶、天貓、京東做的個(gè)性化推薦和客戶消費(fèi)習(xí)慣預(yù)測;此外在教育、醫(yī)療、交通行業(yè)、農(nóng)業(yè)、金融行業(yè)也有很多應(yīng)用,如預(yù)防金融犯罪、預(yù)測農(nóng)產(chǎn)品價(jià)格等等。
 圖為百度交通大數(shù)據(jù)成果展中的出租車運(yùn)力圖(圖片來源:國家測繪地理信息局)
圖為百度交通大數(shù)據(jù)成果展中的出租車運(yùn)力圖(圖片來源:國家測繪地理信息局)
國外也有不少公司在做大數(shù)據(jù),比如Cloudera、MapR、雅虎、Facebook(推出了Hive)、推特、谷歌、IBM等等,應(yīng)用也非常廣泛。國內(nèi)也有不少,比如BAT、京東、美團(tuán)、亞信、去哪兒等。
數(shù)據(jù)妞:對于轉(zhuǎn)型大數(shù)據(jù)的開發(fā)人員有哪些建議?
唐剛:對于想要轉(zhuǎn)型大數(shù)據(jù)開發(fā)的IT人,有以下幾點(diǎn)需要注意:
第一,他最好有一定的開發(fā)經(jīng)歷,不管做哪方面的開發(fā),也不管是Java、.NET、PHP,至少要掌握一門編程語言。因?yàn)榇髷?shù)據(jù)開發(fā)肯定離不開寫代碼。
第二,要對數(shù)據(jù)敏感。做Java開發(fā)、Android開發(fā)更多的是強(qiáng)調(diào)邏輯思維,但是大數(shù)據(jù)開發(fā)不僅強(qiáng)調(diào)邏輯思維,還要對數(shù)字敏感。學(xué)數(shù)學(xué)或相關(guān)專業(yè)的人來做大數(shù)據(jù)是有一定先天優(yōu)勢的,因?yàn)樗斜旧斫?jīng)過多年的學(xué)習(xí),對數(shù)字、數(shù)據(jù)很敏感,很適合做數(shù)據(jù)分析挖掘的工作。如果他想做大數(shù)據(jù)開發(fā),還需要去學(xué)習(xí)一門編程語言,比如Java等等。
數(shù)據(jù)妞:假如我不會(huì)編程語言,數(shù)學(xué)功底也不好,又想從事大數(shù)據(jù)開發(fā)該怎么辦?
唐剛:首先,從掌握一門編程語言開始。關(guān)于編程語言的推薦,我認(rèn)為還是Java比較好。因?yàn)镠adoop目前仍然是大數(shù)據(jù)開發(fā)的主流工具,它的源碼是用Java寫的。而且在掌握J(rèn)ava之后再看Scala(Spark的源碼)就比較簡單了,Scala是一種函數(shù)式編程,掌握J(rèn)ava之后可以更好地理解函數(shù)式編程。
其次,大數(shù)據(jù)開發(fā)不需要用到很高端的數(shù)學(xué)知識,只有機(jī)器學(xué)習(xí)部分會(huì)有一些算法,這些是可以在工作當(dāng)中通過項(xiàng)目實(shí)踐來彌補(bǔ)的。
在職業(yè)規(guī)劃上,我個(gè)人建議如果有機(jī)會(huì)就要去大公司磨練。因?yàn)榇蠊镜募夹g(shù)比較前沿,接觸新技術(shù)的途徑也比較多,可以學(xué)到很多東西,對今后的職業(yè)生涯也有更好的保證。
數(shù)據(jù)妞:想要自學(xué)的話,有什么推薦的書籍和學(xué)習(xí)方式嗎?
唐剛:可以學(xué)習(xí)的書籍太多了,比如《Hadoop權(quán)威指南》。
最好的學(xué)習(xí)途徑其實(shí)就是官方網(wǎng)站,最好的學(xué)習(xí)資料就是官方文檔,要經(jīng)常去Hadoop和Spark的官網(wǎng)看第一手資料。雖然這兩個(gè)官網(wǎng)都是英文的,一開始可能會(huì)讓人覺得吃力,但時(shí)間長了就順了,一方面可以學(xué)到Hadoop和Spark的技術(shù),另一方面還可以提高英文閱讀水平。
 Hadoop官網(wǎng)
Hadoop官網(wǎng)
另外還有一些學(xué)習(xí)方法也是很好的:
有問題多百度,因?yàn)槟阌龅降膯栴}別人在學(xué)習(xí)當(dāng)中也可能會(huì)遇到,所以有什么問題找百度;
多去一些諸如CSDN等優(yōu)秀的技術(shù)網(wǎng)站,這些網(wǎng)站有很多關(guān)于大數(shù)據(jù)開發(fā)的技術(shù)資料;
多看一些技術(shù)大拿寫的博客,學(xué)習(xí)他們的經(jīng)驗(yàn)和方法,包括看他們寫的代碼,學(xué)習(xí)他們解決問題的思路和方法;
大數(shù)據(jù)開發(fā)始終離不開寫代碼,作為一名大數(shù)據(jù)開發(fā)者要多寫代碼,經(jīng)常Coding,加深對技術(shù)的理解和熟練度;
如果公司里有大數(shù)據(jù)項(xiàng)目是非常好的,可以通過項(xiàng)目實(shí)踐的方式來學(xué)習(xí)。
數(shù)據(jù)妞:深入進(jìn)修Hadoop和Spark都要注意什么?
唐剛:到了大數(shù)據(jù)開發(fā)的高端領(lǐng)域是離不開機(jī)器學(xué)習(xí)的,開發(fā)者不僅要寫代碼,還要懂算法,懂算法的實(shí)現(xiàn)過程。Hadoop生態(tài)體系當(dāng)中的Mahout 、Spark生態(tài)體系當(dāng)中的MLlib都是進(jìn)行數(shù)據(jù)挖掘的工具,可以把機(jī)器學(xué)習(xí)的一些算法應(yīng)用到Hadoop和Spark的大數(shù)據(jù)開發(fā)當(dāng)中。
現(xiàn)在咱們常常提到機(jī)器學(xué)習(xí),實(shí)際上這些學(xué)科在以前早就有了,但是當(dāng)時(shí)的數(shù)據(jù)量沒有達(dá)到現(xiàn)在的級別,機(jī)器學(xué)習(xí)的作用還無法得到很好的發(fā)揮。現(xiàn)在進(jìn)入到了大數(shù)據(jù)時(shí)代,機(jī)器學(xué)習(xí)有了更好的“用武之地”。可以說,大數(shù)據(jù)促進(jìn)了機(jī)器學(xué)習(xí)。
數(shù)據(jù)妞:關(guān)于Hadoop和Spark的學(xué)習(xí)路徑可否介紹一下?
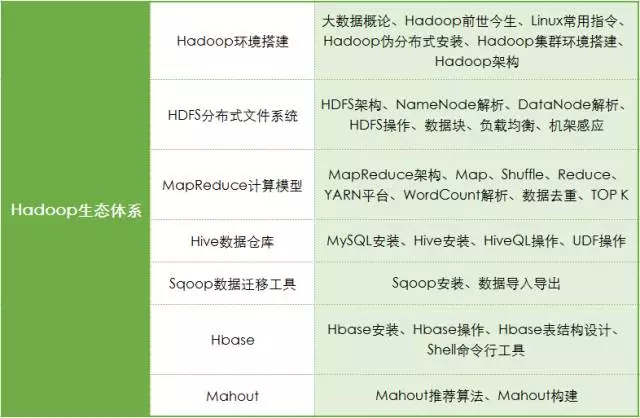
唐剛:Hadoop的一個(gè)大概的學(xué)習(xí)路徑是這樣的:除了搭建集群,首先要學(xué)習(xí)HDFS和YARN平臺,然后是MapReduce、Hive,之后可以學(xué)習(xí)HBase,再往高級可以學(xué)習(xí)Mahout。
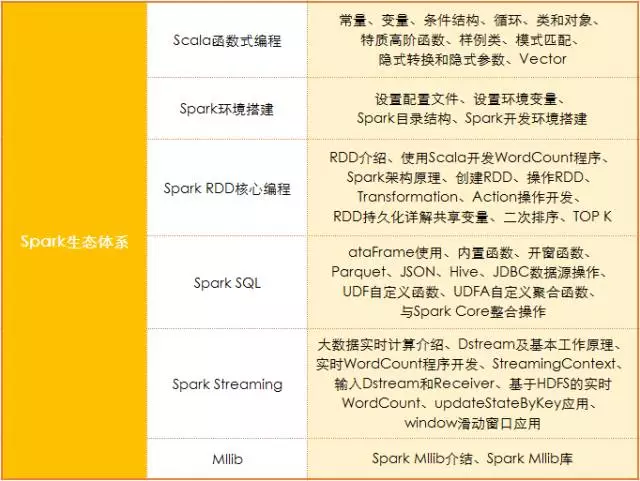
Spark除了搭建集群以外,第一個(gè)要學(xué)習(xí)RDD編程,RDD是彈性分布式數(shù)據(jù)集,然后是Spark SQL,再往下是Spark Streaming,之后是MLlib(相當(dāng)于Hadoop中的Mahout),如果想再繼續(xù)深入可以學(xué)習(xí)圖計(jì)算GraphX。
大數(shù)據(jù)分析和數(shù)據(jù)挖掘則是另外一個(gè)方向,它用到的工具和語言有SAS、SPSS、R語言、Python。
大數(shù)據(jù)分析和大數(shù)據(jù)開發(fā)是兩個(gè)方向,兩套體系,現(xiàn)在最稀缺的還是大數(shù)據(jù)開發(fā)人員。數(shù)據(jù)分析相對來說門檻較低,而大數(shù)據(jù)開發(fā)人員要懂框架、會(huì)寫代碼、有數(shù)據(jù)思維、有邏輯思維,還要懂機(jī)器學(xué)習(xí)的算法,門檻就比較高,這從薪資待遇上來說也有所體現(xiàn)。
唐剛老師: Cloudera原廠授權(quán)講師。北航碩士,10年IT研發(fā)與培訓(xùn)經(jīng)驗(yàn),對Java、Hadoop、Scala、Spark、數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)等大數(shù)據(jù)技術(shù)具有深厚的技術(shù)功底,曾參與開發(fā)電商日志分析、廣告實(shí)時(shí)推薦、金融異常交易預(yù)警、基于GPS的實(shí)時(shí)路況分析、超速頻發(fā)路段監(jiān)控等項(xiàng)目。
5、6年前,大數(shù)據(jù)的概念還不為人所知,Hadoop更是沒幾個(gè)人知道,唐剛老師由于工作上的因緣,幸運(yùn)的成為最早接觸并使用Hadoop進(jìn)行大數(shù)據(jù)開發(fā)的那批人。在后來的日子,他沒有像其他人那樣去大公司做高管或者創(chuàng)業(yè),而是慢慢走上了大數(shù)據(jù)開發(fā)的培訓(xùn)之路。
唐剛老師認(rèn)為技術(shù)講師是一份對人要求更高的工作,不僅要走在技術(shù)的前沿,還要善于講解和表達(dá)。五年多來,他一直在大力推行Hadoop和Spark,但仍有不少人對這兩種開發(fā)工具的運(yùn)用表示困惑或帶有誤解。在采訪中,唐剛老師結(jié)合自己的經(jīng)歷,探討了Hadoop和Spark的優(yōu)劣和應(yīng)用,并給出了學(xué)習(xí)建議和學(xué)習(xí)路徑,數(shù)據(jù)妞希望能對有志轉(zhuǎn)型大數(shù)據(jù)或步入大數(shù)據(jù)行業(yè)的人有所幫助。
數(shù)據(jù)妞:能否談?wù)勀cHadoop的接觸經(jīng)歷?
唐剛:我大學(xué)讀的是計(jì)算機(jī),但那時(shí)候我對編程其實(shí)沒有什么興趣。在學(xué)校里我們學(xué)的是C語言、匯編語言等等,采用的都是DOS界面,非常枯燥。這種感覺直到接觸VB才大大改變,因?yàn)閂B是有可視化效果的,我才覺得原來編程也挺好玩的。后來我又接觸了Java,畢業(yè)之后就一直在做Java開發(fā)。
2010年到2011年那時(shí),我工作的公司要做一個(gè)Java Web的項(xiàng)目,數(shù)據(jù)量非常大,用Java去查詢數(shù)據(jù)的時(shí)候速度非常慢,我們就想辦法如何去解決這個(gè)問題。那段時(shí)間我在一個(gè)國外的技術(shù)網(wǎng)站上看到了Hadoop,我才知道原來還有這樣一個(gè)東西,它可以有效提升數(shù)據(jù)處理的速度,于是我在一次公司例會(huì)上提議學(xué)習(xí)Hadoop。
那時(shí)候國內(nèi)幾乎沒人用Hadoop,就連知道的人也很少,我們學(xué)習(xí)途徑主要就通過Hadoop的官方網(wǎng)站。另外幸運(yùn)的是,我有一個(gè)朋友當(dāng)時(shí)在讀研,他的研究生畢業(yè)論文就是要用Hadoop 去做的,于是我有什么問題就向這個(gè)朋友討教。
我們大概花了半年時(shí)間才完成了轉(zhuǎn)型,可以說非常吃力。一是當(dāng)時(shí)學(xué)習(xí)途徑很狹窄,沒有中文資料,也沒有什么書籍,資料匱乏,一個(gè)組件可能就要研究很長時(shí)間。二是時(shí)間少,我要在完成本職工作之后再抽時(shí)間一點(diǎn)一點(diǎn)學(xué)。不過雖然辛苦,但帶給我最大的好處就是我很早就與大數(shù)據(jù)開發(fā)結(jié)緣。
數(shù)據(jù)妞:您目前的工作是什么,為何有這樣的職業(yè)選擇?
唐剛:目前我在光環(huán)國際擔(dān)任大數(shù)據(jù)教學(xué)總監(jiān),主要工作是針對大數(shù)據(jù)開發(fā)方面的培訓(xùn)。
以前和我一起學(xué)習(xí)Hadoop的人現(xiàn)在基本都混得很不錯(cuò),有不少人都在做CTO或是總監(jiān)級別的了。而我是因?yàn)樵?011年之前曾在一些培訓(xùn)機(jī)構(gòu)兼職講課,從那時(shí)候開始就漸漸喜歡上了講課,于是我跳槽之后就去了一家IT培訓(xùn)公司,一邊大力推廣Hadoop,一邊做大數(shù)據(jù)項(xiàng)目的研發(fā)。
我認(rèn)為做技術(shù)講師是一件高難度的工作。做技術(shù)講師首先要懂技術(shù),要保持自己技術(shù)的先進(jìn)性,其次你要能準(zhǔn)確、合適地進(jìn)行表達(dá),因?yàn)榧夹g(shù)是很抽象、很枯燥、很難理解的東西,你需要用近似于“大白話”的方式去說明專業(yè)的技術(shù)問題,這個(gè)對人的提高是很大的。我現(xiàn)在也一直在研究前沿技術(shù),最近我一直在研究Spark和機(jī)器學(xué)習(xí)。
數(shù)據(jù)妞:您認(rèn)為是什么造成了Hadoop的流行?
唐剛:Hadoop之所以能流行主要是因?yàn)榇髷?shù)據(jù)對存儲、處理的要求比傳統(tǒng)數(shù)據(jù)要高得多。
由于互聯(lián)網(wǎng)(特別是移動(dòng)互聯(lián)網(wǎng))的發(fā)展,每天都會(huì)產(chǎn)生大量的數(shù)據(jù),產(chǎn)生數(shù)據(jù)的渠道比之前也多了很多。這些數(shù)據(jù)通過日積月累就會(huì)變成海量的大數(shù)據(jù)。
2011年全球被創(chuàng)建和復(fù)制的數(shù)據(jù)總量為1.8ZB(10的21次方),其中75%來自于個(gè)人,遠(yuǎn)遠(yuǎn)超過人類有史以來所有印刷材料的數(shù)據(jù)總量(200PB)。過去幾年全世界產(chǎn)生的數(shù)據(jù)量甚至超過了歷史上2萬年來產(chǎn)生的數(shù)據(jù)量的總和。(資料來源:IDC研究報(bào)告《從混沌中提取價(jià)值》)
現(xiàn)在人們常說的數(shù)據(jù)挖掘、數(shù)據(jù)分析并不是新的東西,在之前已經(jīng)存在很久了。但大數(shù)據(jù)時(shí)代和以前不一樣,大數(shù)據(jù)如果還用以前的手段進(jìn)行存儲、分析是很困難的。然而Hadoop在處理海量大數(shù)據(jù)方面就非常有優(yōu)勢,所以可以說Hadoop是應(yīng)大數(shù)據(jù)時(shí)代之勢而流行起來。
Hadoop的優(yōu)勢主要體現(xiàn)在兩方面:第一,它可以通過HDFS把數(shù)據(jù)進(jìn)行分布式的存儲,這就解決了大數(shù)據(jù)的存儲問題;第二,它有MapReduce,通過編寫Map函數(shù)和Reduce函數(shù)解決了大數(shù)據(jù)的計(jì)算處理問題。目前Hadoop在大數(shù)據(jù)開發(fā)領(lǐng)域仍然占主流。
數(shù)據(jù)妞:Spark是何時(shí)發(fā)展起來的?Spark會(huì)取代Hadoop嗎?
唐剛:Spark大概是在2013年傳入中國的,在2014年左右就出現(xiàn)了一些觀點(diǎn),認(rèn)為Spark會(huì)取代Hadoop,或者“Spark一出,Hadoop必死”。但是我始終認(rèn)為,大數(shù)據(jù)開發(fā)這個(gè)行業(yè)肯定是百家爭鳴、多平臺共存的行業(yè)。直到目前,我們也發(fā)現(xiàn)Hadoop并沒有因?yàn)镾park的出現(xiàn)而消亡,Hadoop和 Spark都有它的優(yōu)勢和劣勢。
從數(shù)據(jù)存儲的角度來看:目前Spark生態(tài)體系中缺少一個(gè)類似于Hadoop的HDFS的子項(xiàng)目。HDFS(文件分布式系統(tǒng))屬于Hadoop生態(tài)體系的,是一個(gè)非常優(yōu)秀的分布式文件系統(tǒng),解決了大數(shù)據(jù)的存儲問題,還有YARN平臺也是一個(gè)非常優(yōu)秀的資源管理系統(tǒng)。Spark缺少像HDFS這樣一個(gè)框架,所以Spark要依賴于HDFS來進(jìn)行存儲。Spark在進(jìn)行開發(fā)時(shí)也會(huì)用到Y(jié)ARN平臺或者M(jìn)esos。
從數(shù)據(jù)處理速度的角度看:相比Spark,Hadoop最大的問題是處理速度慢。MapReduce產(chǎn)生的中間結(jié)果是放到磁盤當(dāng)中的,如果我要用到Map產(chǎn)生的中間結(jié)果,我需要先從磁盤中讀取到內(nèi)存中再使用,如果又產(chǎn)生一個(gè)中間結(jié)果,這個(gè)中間結(jié)果又要先放到磁盤當(dāng)中,再從磁盤讀取到內(nèi)存當(dāng)中才能使用,所以說MapReduce存在無法避免的磁盤輸入輸出的過程,這在速度上是一個(gè)很大的缺陷。
但是Spark就不一樣了。Spark處理數(shù)據(jù)所產(chǎn)生的中間結(jié)果放在內(nèi)存中,要用的時(shí)候直接從內(nèi)存讀取就可以了,少了磁盤輸入輸出的過程,速度比Hadoop要快。
從編碼的角度看:在MapReduce中,需要編寫Map函數(shù)和Reduce函數(shù),不管做什么處理,必須編寫這2個(gè)函數(shù)。Hadoop的源碼是Java,用Java編寫MapReduce比較麻煩、繁瑣,有時(shí)候代碼量也挺大的。
Spark的源碼是Scala,Scala寫起來比較簡潔,所以用Scala來開發(fā)Spark要簡單得多。
Hadoop在目前大數(shù)據(jù)開發(fā)的領(lǐng)域仍然占主流,但是Spark的發(fā)展速度是非常快的,它是一個(gè)非常有發(fā)展?jié)摿Φ目蚣堋adoop更加偏向于離線批處理,Spark既可以進(jìn)行離線批處理計(jì)算,也可以進(jìn)行交互式計(jì)算,還可以對數(shù)據(jù)流進(jìn)行準(zhǔn)實(shí)時(shí)計(jì)算。
數(shù)據(jù)妞:國內(nèi)外對Hadoop和Spark的應(yīng)用情況如何?
唐剛:Hadoop、Spark的實(shí)際應(yīng)用有很多。包括政府的輿情管理,例如我國的網(wǎng)絡(luò)輿情監(jiān)測系統(tǒng);電信行業(yè),例如移動(dòng)、聯(lián)通這樣的電信運(yùn)營商做精準(zhǔn)營銷(客戶畫像、關(guān)系鏈研究、實(shí)時(shí)營銷和個(gè)性化推薦等);電商行業(yè),如淘寶、天貓、京東做的個(gè)性化推薦和客戶消費(fèi)習(xí)慣預(yù)測;此外在教育、醫(yī)療、交通行業(yè)、農(nóng)業(yè)、金融行業(yè)也有很多應(yīng)用,如預(yù)防金融犯罪、預(yù)測農(nóng)產(chǎn)品價(jià)格等等。
圖為百度交通大數(shù)據(jù)成果展中的出租車運(yùn)力圖(圖片來源:國家測繪地理信息局)
國外也有不少公司在做大數(shù)據(jù),比如Cloudera、MapR、雅虎、Facebook(推出了Hive)、推特、谷歌、IBM等等,應(yīng)用也非常廣泛。國內(nèi)也有不少,比如BAT、京東、美團(tuán)、亞信、去哪兒等。
數(shù)據(jù)妞:對于轉(zhuǎn)型大數(shù)據(jù)的開發(fā)人員有哪些建議?
唐剛:對于想要轉(zhuǎn)型大數(shù)據(jù)開發(fā)的IT人,有以下幾點(diǎn)需要注意:
第一,他最好有一定的開發(fā)經(jīng)歷,不管做哪方面的開發(fā),也不管是Java、.NET、PHP,至少要掌握一門編程語言。因?yàn)榇髷?shù)據(jù)開發(fā)肯定離不開寫代碼。
第二,要對數(shù)據(jù)敏感。做Java開發(fā)、Android開發(fā)更多的是強(qiáng)調(diào)邏輯思維,但是大數(shù)據(jù)開發(fā)不僅強(qiáng)調(diào)邏輯思維,還要對數(shù)字敏感。學(xué)數(shù)學(xué)或相關(guān)專業(yè)的人來做大數(shù)據(jù)是有一定先天優(yōu)勢的,因?yàn)樗斜旧斫?jīng)過多年的學(xué)習(xí),對數(shù)字、數(shù)據(jù)很敏感,很適合做數(shù)據(jù)分析挖掘的工作。如果他想做大數(shù)據(jù)開發(fā),還需要去學(xué)習(xí)一門編程語言,比如Java等等。
數(shù)據(jù)妞:假如我不會(huì)編程語言,數(shù)學(xué)功底也不好,又想從事大數(shù)據(jù)開發(fā)該怎么辦?
唐剛:首先,從掌握一門編程語言開始。關(guān)于編程語言的推薦,我認(rèn)為還是Java比較好。因?yàn)镠adoop目前仍然是大數(shù)據(jù)開發(fā)的主流工具,它的源碼是用Java寫的。而且在掌握J(rèn)ava之后再看Scala(Spark的源碼)就比較簡單了,Scala是一種函數(shù)式編程,掌握J(rèn)ava之后可以更好地理解函數(shù)式編程。
其次,大數(shù)據(jù)開發(fā)不需要用到很高端的數(shù)學(xué)知識,只有機(jī)器學(xué)習(xí)部分會(huì)有一些算法,這些是可以在工作當(dāng)中通過項(xiàng)目實(shí)踐來彌補(bǔ)的。
在職業(yè)規(guī)劃上,我個(gè)人建議如果有機(jī)會(huì)就要去大公司磨練。因?yàn)榇蠊镜募夹g(shù)比較前沿,接觸新技術(shù)的途徑也比較多,可以學(xué)到很多東西,對今后的職業(yè)生涯也有更好的保證。
數(shù)據(jù)妞:想要自學(xué)的話,有什么推薦的書籍和學(xué)習(xí)方式嗎?
唐剛:可以學(xué)習(xí)的書籍太多了,比如《Hadoop權(quán)威指南》。
最好的學(xué)習(xí)途徑其實(shí)就是官方網(wǎng)站,最好的學(xué)習(xí)資料就是官方文檔,要經(jīng)常去Hadoop和Spark的官網(wǎng)看第一手資料。雖然這兩個(gè)官網(wǎng)都是英文的,一開始可能會(huì)讓人覺得吃力,但時(shí)間長了就順了,一方面可以學(xué)到Hadoop和Spark的技術(shù),另一方面還可以提高英文閱讀水平。
Hadoop官網(wǎng)
另外還有一些學(xué)習(xí)方法也是很好的:
有問題多百度,因?yàn)槟阌龅降膯栴}別人在學(xué)習(xí)當(dāng)中也可能會(huì)遇到,所以有什么問題找百度;
多去一些諸如CSDN等優(yōu)秀的技術(shù)網(wǎng)站,這些網(wǎng)站有很多關(guān)于大數(shù)據(jù)開發(fā)的技術(shù)資料;
多看一些技術(shù)大拿寫的博客,學(xué)習(xí)他們的經(jīng)驗(yàn)和方法,包括看他們寫的代碼,學(xué)習(xí)他們解決問題的思路和方法;
大數(shù)據(jù)開發(fā)始終離不開寫代碼,作為一名大數(shù)據(jù)開發(fā)者要多寫代碼,經(jīng)常Coding,加深對技術(shù)的理解和熟練度;
如果公司里有大數(shù)據(jù)項(xiàng)目是非常好的,可以通過項(xiàng)目實(shí)踐的方式來學(xué)習(xí)。
數(shù)據(jù)妞:深入進(jìn)修Hadoop和Spark都要注意什么?
唐剛:到了大數(shù)據(jù)開發(fā)的高端領(lǐng)域是離不開機(jī)器學(xué)習(xí)的,開發(fā)者不僅要寫代碼,還要懂算法,懂算法的實(shí)現(xiàn)過程。Hadoop生態(tài)體系當(dāng)中的Mahout 、Spark生態(tài)體系當(dāng)中的MLlib都是進(jìn)行數(shù)據(jù)挖掘的工具,可以把機(jī)器學(xué)習(xí)的一些算法應(yīng)用到Hadoop和Spark的大數(shù)據(jù)開發(fā)當(dāng)中。
現(xiàn)在咱們常常提到機(jī)器學(xué)習(xí),實(shí)際上這些學(xué)科在以前早就有了,但是當(dāng)時(shí)的數(shù)據(jù)量沒有達(dá)到現(xiàn)在的級別,機(jī)器學(xué)習(xí)的作用還無法得到很好的發(fā)揮。現(xiàn)在進(jìn)入到了大數(shù)據(jù)時(shí)代,機(jī)器學(xué)習(xí)有了更好的“用武之地”。可以說,大數(shù)據(jù)促進(jìn)了機(jī)器學(xué)習(xí)。
數(shù)據(jù)妞:關(guān)于Hadoop和Spark的學(xué)習(xí)路徑可否介紹一下?
唐剛:Hadoop的一個(gè)大概的學(xué)習(xí)路徑是這樣的:除了搭建集群,首先要學(xué)習(xí)HDFS和YARN平臺,然后是MapReduce、Hive,之后可以學(xué)習(xí)HBase,再往高級可以學(xué)習(xí)Mahout。
Spark除了搭建集群以外,第一個(gè)要學(xué)習(xí)RDD編程,RDD是彈性分布式數(shù)據(jù)集,然后是Spark SQL,再往下是Spark Streaming,之后是MLlib(相當(dāng)于Hadoop中的Mahout),如果想再繼續(xù)深入可以學(xué)習(xí)圖計(jì)算GraphX。
大數(shù)據(jù)分析和數(shù)據(jù)挖掘則是另外一個(gè)方向,它用到的工具和語言有SAS、SPSS、R語言、Python。
大數(shù)據(jù)分析和大數(shù)據(jù)開發(fā)是兩個(gè)方向,兩套體系,現(xiàn)在最稀缺的還是大數(shù)據(jù)開發(fā)人員。數(shù)據(jù)分析相對來說門檻較低,而大數(shù)據(jù)開發(fā)人員要懂框架、會(huì)寫代碼、有數(shù)據(jù)思維、有邏輯思維,還要懂機(jī)器學(xué)習(xí)的算法,門檻就比較高,這從薪資待遇上來說也有所體現(xiàn)。
Copyright 2001-2023 aura.cn
版權(quán)所有 光環(huán)國際·廣州光環(huán)
PMI, PMP, PgMP, PMI-ACP, and PMBOK are registered marks of the Project Management Institute, Inc.






